By Jianshen Liu, CROSS Research Fellow for Eusocial Storage Device project
A Media-based Work Unit (MBWU) is a platform-independent but media- and workload-dependent metric used as a reference point for performance normalization. The CROSS Eusocial Devices project team recently published a paper (MBWU: Benefit Quantification for Data Access Function Offloading) illustrating in detail the motivation and usage of this performance measurement unit. In this two-part blog post, we will focus on the external caching effects that relate to the construction of this measurement unit. This first post will specifically explore why the external caching effects matter and what are the current trade-offs of possible solutions.
Why External Caching Effects Matter
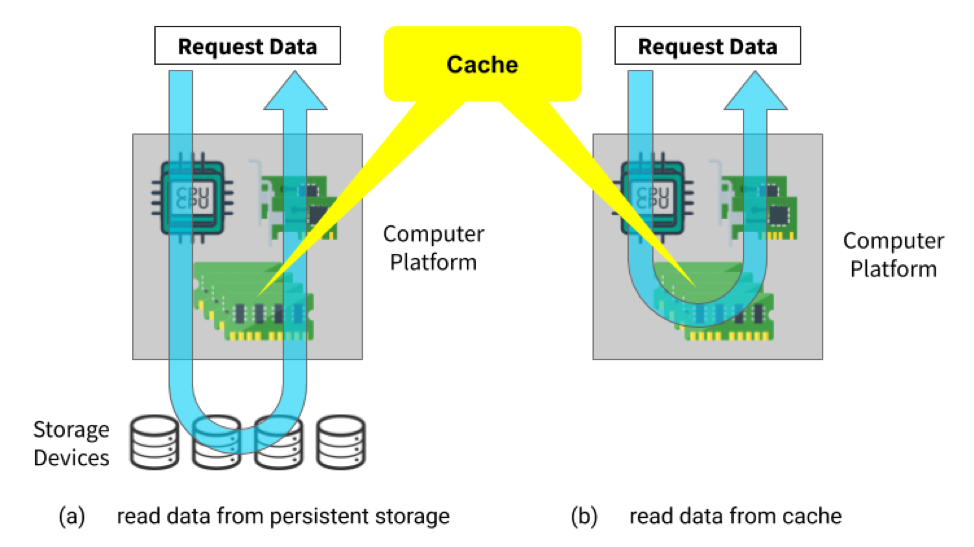
One important requirement of constructing a MBWU for a real-world workload is to ensure that the value of it is platform-independent, which is not a trivial endeavor. For example, the performance numbers on the specification of a storage device, namely the maximum throughput and the maximum I/O operations per second (IOPS), are thought to be platform-independent. However, these numbers are measured under a standard workload pattern that is ideal for storage devices—fixed queue depth with 4 KB block size for random access test and 128 KB block size for sequential access test [1]. While both MBWU and these numbers are platform-independent, the performance numbers on the specification, unlike MBWU, do not represent the performance of real-world workloads. When measuring the performance of a given workload on a platform, the computing resources of the platform—such as the horsepower of the CPU, the capacity and bandwidth of the dynamic random-access memory (DRAM), and the bandwidth of the network interface card (NIC), may have a different impact on the performance evaluation result for the workload. To assess whether the CPU or the NIC is the bottleneck of the workload, we can use system administration tools such as top(1) [2], iostat(1) [3], and sar(1) [4] to check the utilization of these resources. However, the memory utilization of an application is not immediately obvious. Besides the memory that the application allocates for its own use, whenever it uses the file system from kernel to persist data, the file system will use memory as page cache [5] on behalf of the application. This part of memory occupation is accounted for as system memory usage, even though it is the application using this cache during the performance evaluation. Since the system manages the file system cache, in Linux this part of the cache can use as much memory as the system has. For example, if the system has 4 GB of physical memory, the file system cache can use all remaining memory of the 4 GB. This platform-dependent cache utilization causes the performance result of the workload under test depending on the platform. Figure 1 shows a typical data access flow in a system. When the data is first accessed, the system reads it from persistent storage and caches the result in the memory before returning the data to the caller program (Figure 1 (a)). When the program requests the same piece of data next time, the system just reads the data from the cache instead of going through the same I/O path as the first access (Figure 1 (b)). This caching effect directly causes the workload performance correlating with the platform memory capacity. The greater memory capacity the platform has, the higher the workload performance can achieve because more data is accessible from the cache. If the data is all cached, the workload performance only reflects the performance of the memory instead of the performance of the storage media as MBWU requires.
Trade-Offs of Possible Solutions
We should only care about those caching effects coming from accessing the system page cache without accessing the persistent storage. There are several types of caches we should be careful about when dealing with the caching effects. First, for those I/O operations that do not create page caches (e.g., direct I/O, and direct access I/O for memory-like block devices), we should preserve the semantics of the
operations. Second, for the disk cache that most modern storage devices are equipped with, we should preserve the normal processing procedures of the cache since it belongs to the capability of these devices. Third, if the cached pages are created by service routines of the operating system, or programs that are not related to the application under test, we should keep them intact and leave the control to the operating system. Because changing the caching behavior of other programs residing in the same system may cause unexpected performance impacts to the application under test. Finally, eliminating caching effects does not mean disabling the file system page cache. The page cache can be generated following the cache management policy, including but not limited to, readahead, and used as long as the workload performance results are not depending on the platform memory capacity.
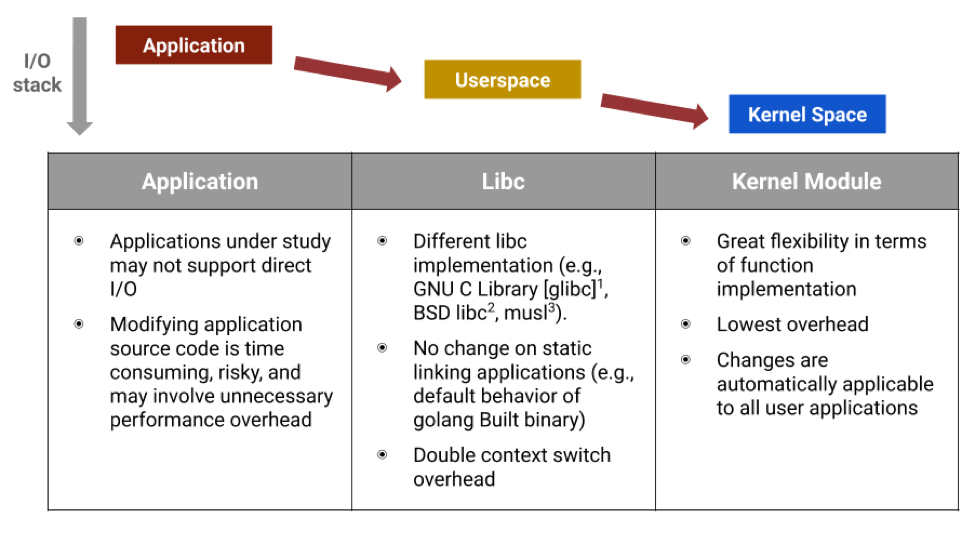
Figure 2: Trade-Offs of Eliminating External Caching Effects in Different Levels within the I/O Stack
1 https://en.wikipedia.org/wiki/GNU_C_Library;
To eliminate external page effects, there are multiple levels in the I/O stack we can operate on from the application under test to the kernel space inside of the operating system, although each option comes with trade-offs (Figure 2).
A naive option is to change all I/O requests from the application under test to direct I/Os, since direct I/O does not create page cache. This would work only if we fix a small set of applications that are allowed to be used by the MBWU-based measurement methodology. However, this methodology is designed to evaluate real-world applications that are unknown upfront. We do not want to put any restrictions on what applications should be used to generate the workload and what applications should be used to process the workload. Since we cannot ask users who would like to construct MBWU to figure out how to modify the application code to use direct I/O, changing all the application I/O to direct I/O is not scalable without knowing what workload to run.
The second option we may consider is to intercept and change the I/O behavior from within libc. Libc is a basic dependency for most applications to interact with the system kernel including storage I/O operations. Changing the I/O behavior of the libc used by the application under test can transparently change the I/O behavior of the application. However, there are multiple implementations of the libc specification in Linux. The GNU C library, or glibc, is just one of those popular implementations. For example, BSD Linux has its own default implementation of libc called BSD libc. Musl is a lightweight libc for operating systems based on the Linux kernel designed to allow efficient static linking. These different implementations of libc increase the cost to maintain the compatibility of the MBWU-based measurement methodology for different applications. Moreover, some applications may be built with static linking to libc, which makes them immutable to any changes to the system installed libc libraries.
Finally, since changing in user-space is not feasible, the remaining option to alter the I/O behavior is to change within the kernel space. Considering that one of the goals of the MBWU-based measurement methodology is to provide an automation framework to enable results reproducibility, there is a handful of interfaces provided by the vanilla kernel that can change how Linux manages the page cache. We analyze the trade-offs of these interfaces as follows:
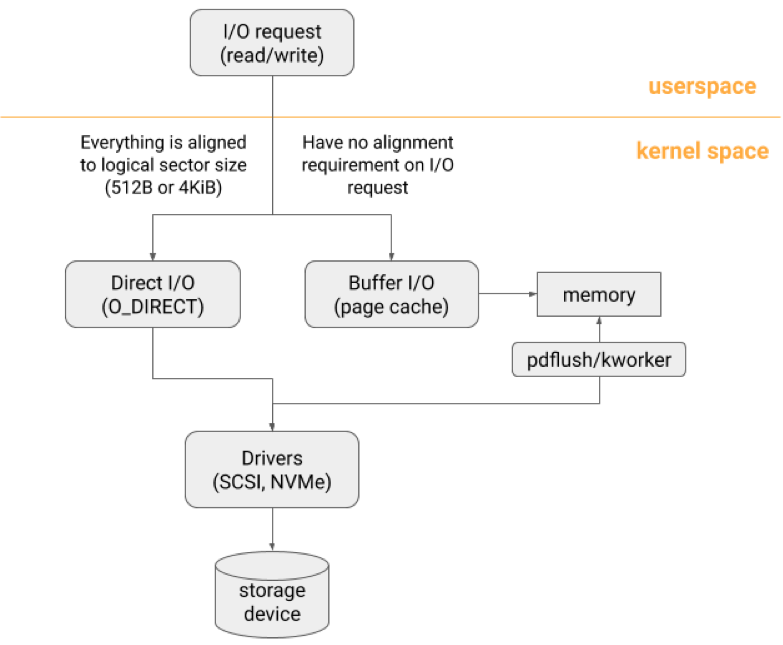
Direct I/O: This is an appealing option as it can bypass the page cache by directly moving the data block on disks to user buffers of a given process. In a nutshell, direct I/O differs from the normal buffer I/O in the locations of the data buffers. Direct I/O requires user-space programs to manage the data buffers by themselves, while buffer I/O manages the buffers within the kernel. To use direct I/O, applications have to ensure that the request count in bytes, the file offset, and the allocated buffer size are aligned on a logical sector size boundary [6, 7] (Figure 3). In most storage devices, this boundary is 512 bytes or 4 KiB. To create a user buffer with the size of a multiple of the logical sector size, the program has to specifically call different memory allocation functions such as aligned_alloc() or posix_memalign(), instead of malloc() and realloc() as these only guarantee the returning memory address is 8-byte aligned. The reason why buffer I/O does not have such a requirement is that the kernel modifies the requests internally to help to conform the same requirement behind the scenes. Specifically, the kernel performs read-modify-write for the incoming data reads and writes if they are not properly aligned. Since the requirement is fundamentally a requirement of storage devices, we cannot simply convert the application issued file I/O to the direct I/O even within the kernel space without ensuring the I/O is logical sector size aligned.
Sysctl files from the virtual memory (VM) subsystem: There are multiple sysctl files under /proc/sys/vm that can change how the kernel manages the page cache. File drop_caches can be used to drop clean pagecache and slab objects depending on the value written to this file. Files with the prefix of dirty_, such as dirty_bytes, dirty_background_bytes, and dirty_expire_centisecs, can control when to write out dirty pages from cache to the underlying persistent storage [8]. However, these interfaces are system-wide configurations, irrespective of what applications generated the dirty pages. That is, the application-natural perspective of these interfaces goes against the third requirement we discussed previously on eliminating the external caching effects.
File memory.limit_in_bytes in cgroup: This interface is used to control the memory usage including page cache for processes assigned to a cgroup [9]. While it can limit the size of page cache used by an application, it also limits the memory usage of the application itself. Eliminating the external caching effects should not intervene in how the application uses its own memory since it is part of the workload to be evaluated.
POSIX_FADV_DONTNEED: This is a useful value for the parameter advice in the system call fadvise64_64(2). The following example is a user program demonstrating the usage of this system call with POSIX_FADV_DONTNEED to free cache pages associated with the region that covering the input file.
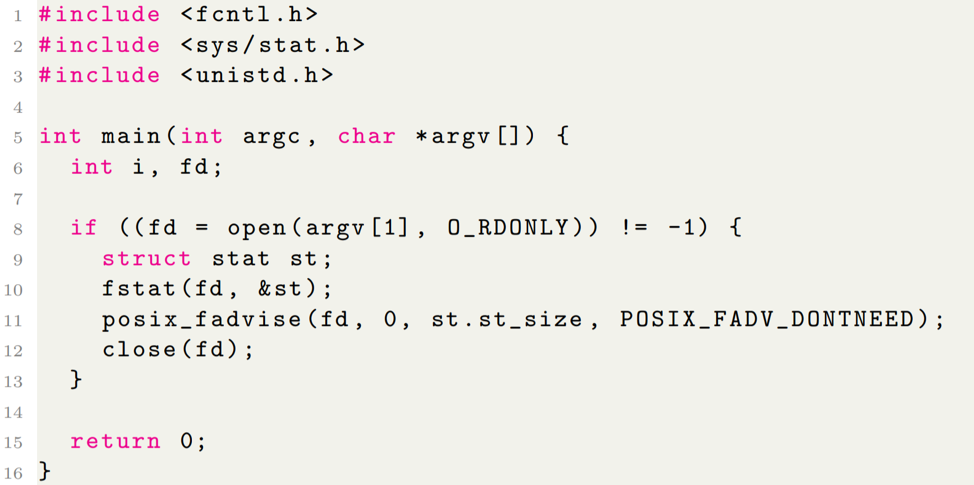
This system call works by writing back dirty pages within the specified range asynchronously before freeing the pages. Therefore, after this call returns, clean pages within the range will be freed as expected while dirty pages may still remain in the cache since they very likely have not been written back to persistent storage by the time when the page cache freeing logic takes place. This system call is very useful because it gives you fine-grained control on the range of page cache you want to remove. Once the page cache for the specified data is freed, the system is required to read from persistent storage for the same piece of data again if it is requested.
sync_file_range(2): This system call enables programs to control when and how to synchronize dirty pages of a file. It differs from sync(8) [10] in that it can specify the range of pages within a file to be written to disk if they are dirty. When this call returns, the victim pages are marked as clean pages so that they can be at any time revoked by the kernel following the regular cache management policy. Note that this system call does not flush disk write cache that is maintained by storage devices. The cache flushing threads from the kernel (kworker or pdflush), however, write back dirty pages all the way down to the spinning media in disks or flash chips in SSDs to ensure the completion of file integrity. Thus, the write-back level of this system call is shallower than the cache flushing threads (Figure 3).
Conclusion
We analyzed the trade-offs of different options to eliminate the page caching effects in the entire I/O stack—from the application that processes the test workload to the kernel space that manages the details of page caches. The sustainable option is to make changes within the kernel space because of its effectiveness on transparency and reliability. There are multiple page-caching related interfaces provided by the kernel as we discussed. In the next blog post, we will explore how to change the behavior of buffer I/O by implementing a kernel module that uses some of these interfaces to deal with the page caching effects.
References
[1] Samsung Electronics Co., Ltd. Samsung PM863a/SM863a SSD for data centers, November 2016.
[2] top(1): tasks - Linux man page. https://linux.die.net/man/1/top.
[3] iostat(1) - Linux man page. https://linux.die.net/man/1/iostat.
[4] sar(1) - Linux man page. https://linux.die.net/man/1/sar.
[5] Wikipedia contributors. Page cache — Wikipedia, the free encyclopedia. https://en.wikipedia.org/w/index.php?title=Page_cache&oldid=919726591, 2019. [Online; accessed 4-November-2019].
[6] Mike Snitzer. I/o limits: block sizes, alignment and i/o hints. https://people.redhat.com/msni tzer/docs/io-limits.txt.
[7] Considerations for the use of direct I/O (O DIRECT). https://www.ibm.com/support/knowledgecenter/en/STXKQY_4.2.0/com.ibm.spectrum.scale.v4r2.adm.doc/bl1adm_considerations_direct_io.htm.
[8] Documentation for /proc/sys/vm - the linux kernel archives. https://www.kernel.org/doc/Docum entation/sysctl/vm.txt.
[9] Cgroups - the linux kernel archives. https://www.kernel.org/doc/Documentation/cgroup-v1/memory.txt.
[10] sync(8) - Linux man page. https://linux.die.net/man/8/sync.
