By Jianshen Liu, CROSS Research Fellow for Eusocial Storage Device project
In my previous post Design Considerations of Eliminating External Caching Effects for MBWU Construction, I discussed the background as to why we need to eliminate the page caching effects during the construction of a MBWU, as well as the possible alternatives to deal with the page caching issue. As noted in that post, the CROSS Eusocial Devices project team published a paper in December 2019 (MBWU: Benefit Quantification for Data Access Function Offloading) which illustrated the motivation and usage of this performance measurement unit. Please go check out this paper if you would like to know about how we compare the performance of a given workload on different platforms with a MBWU-based measurement methodology. This post as a continuation of previous discussion, we will present the implementation of a kernel module, named no_fscache, for eliminating the caching effects by emulating the I/O behavior under insufficient memory for the file system page cache. We demonstrate the precision of emulation with our most recent results as part of the on-going experiments at the end of the post.
Define the Goal
The high-level goal is to eliminate the page caching effects for a given user application that issues I/O requests to a specific storage device. Without the page caching effects, the performance of the workload processed by the application should be consistent regardless of the physical memory capacity of the platform that the application runs on. In practice, this goal is ambiguous given there are multiple interfaces that can be used to change the kernel I/O behavior. One important signal we found was that the page caching effects reduce as the pressure of the system memory increases. Specifically, for every new read or write request to the kernel, the smaller the system memory capacity, the smaller the page caching effect on the request will be. This is because if the amount of available memory for the page cache is small, the chance that a new read or write request from applications finds the cache of the request in the memory is also small. Therefore, the request most likely has to access data from the underlying storage devices instead of cache. With this knowledge, we can translate our initial goal into a fine-grained version: Minimize the page caching effects through emulating the I/O behavior under memory insufficiency by having changes within the kernel space.
Implementation
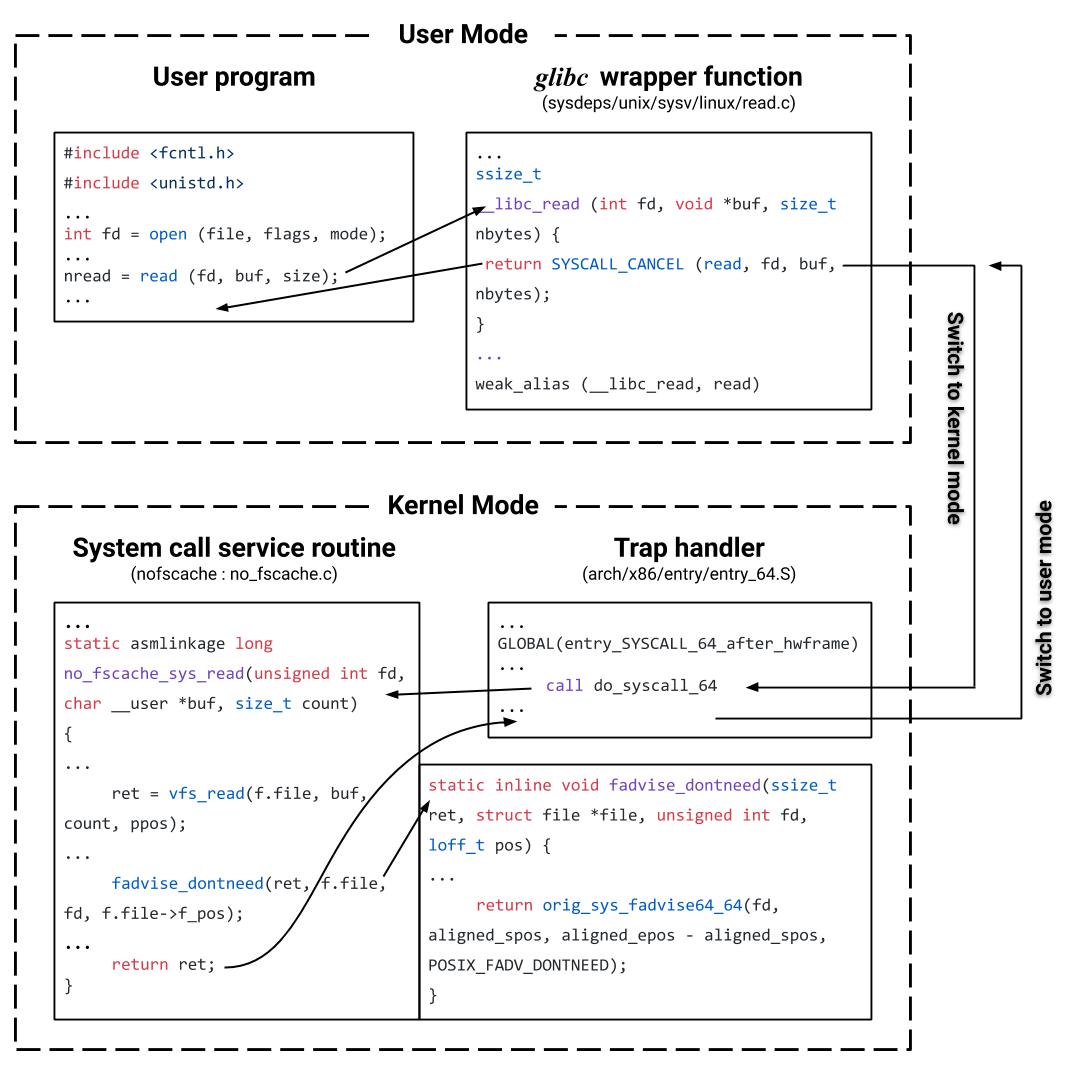
To emulate the situation of memory insufficiency for page cache, we need to understand how the kernel manages the page cache during the process of I/O requests. For read requests, when the memory is insufficient, the kernel needs to evict some of the old page caches to make room for the data that is currently being requested. Once the data is retrieved from storage devices, the kernel writes the data into the clean page slots that are erased before, and finally copies these page caches to the user-space buffer specified at the beginning of the requests. We can emulate this series of operations by using the system call fadvise64_64(2) with POSIX_FADV_DONTNEED as the value of the parameter advice (Figure 1). A user program can call the regular POSIX read(2) to access the data of interest as usual, and the kernel will handle the actual work by executing the normal system call service routine. But before the service routine returns the result to the user program, we call fadvise64_64() to remove the range of page cache generated by the normal read operation. Therefore, by the time when the user program gets the response, the cache of the requested data is no longer in the memory. This cache elimination mechanism ensures that whenever the same piece of data is requested again by either read or write in the future, the process will go through the same I/O path as if the data has never been accessed before. Therefore, we can always read data from storage devices instead of memory cache.
For write requests, we do not use the same system call to remove the victim page caches because the kernel uses a different policy to manage dirty memory. This policy is defined by a set of sysctl files under the Linux VM subsystem [8]. We have discussed some of the files in the previous section “Trade-Offs of Possible Solutions”. For example, file dirty_bytes specifies the amount of dirty memory at which a process generating disk writes will itself start writeback. In other words, the dirty pages of a process are required to be flushed to persistent storage by the process itself at the time of write instead of waiting for the kernel cache flushing threads to clean them up. File dirty_ratio provides a similar control on the percentage of the total system memory that can be dirty. By default, this ratio is set to 20% which when reaches, the process doing writes would be blocked and writes out dirty pages to the persistent storage. This memory management policy implies the procedure the system will perform when the memory is insufficient for dirty pages. To emulate the I/O path of write under memory insufficiency, we can call sync_file_range(2) to flush the dirty pages at the time of write before returning the result to the caller program in the user-space (Figure 2). Note that the memory management policy does not involve freeing up the corresponding page caches when the dirty memory exceeds the specified value of dirty_ratio. Since calling the system call sync_file_range(2) only converts the state of the specified range of page caches from dirty to clean by writing out pages to underlying storage devices, the use of this system call compliant with the default memory management policy thus emulating the I/O path under memory insufficiency.
Compatibility with Linux I/O Models
The method described above conducts the elimination of page caching effects at the end of I/O system calls. Since the elimination process is synchronous, we need to analyze the compatibility of this method in terms of four different types of I/O models (Figure 3) in Linux.
The most common I/O model is the synchronous blocking I/O model. In this case, when an application issues a read or a write system call, the application is blocked in the current thread until the kernel notifies the application that the request is complete. The system changes the state of the application process to I/O wait while it is waiting for the data being copied from or written to storage devices. For reads, the kernel puts the returned data in the page cache and copies the data segment to user-space based on the current file offset and the length of bytes in the request. For writes, dirty pages will be flushed to disks in synchronous writes, or they just stay in the cache and wait for the next round of flush activity orchestrated by the kernel. This model is the most common model because it has been using for decades by many applications. Our method to eliminate caching effects naturally fit in this model because the elimination is done before applications aware the issued requests have been completed. This model consists of four pairs of read/write synchronous interfaces, and we have augmented these interfaces with functions to eliminate page caching effects.
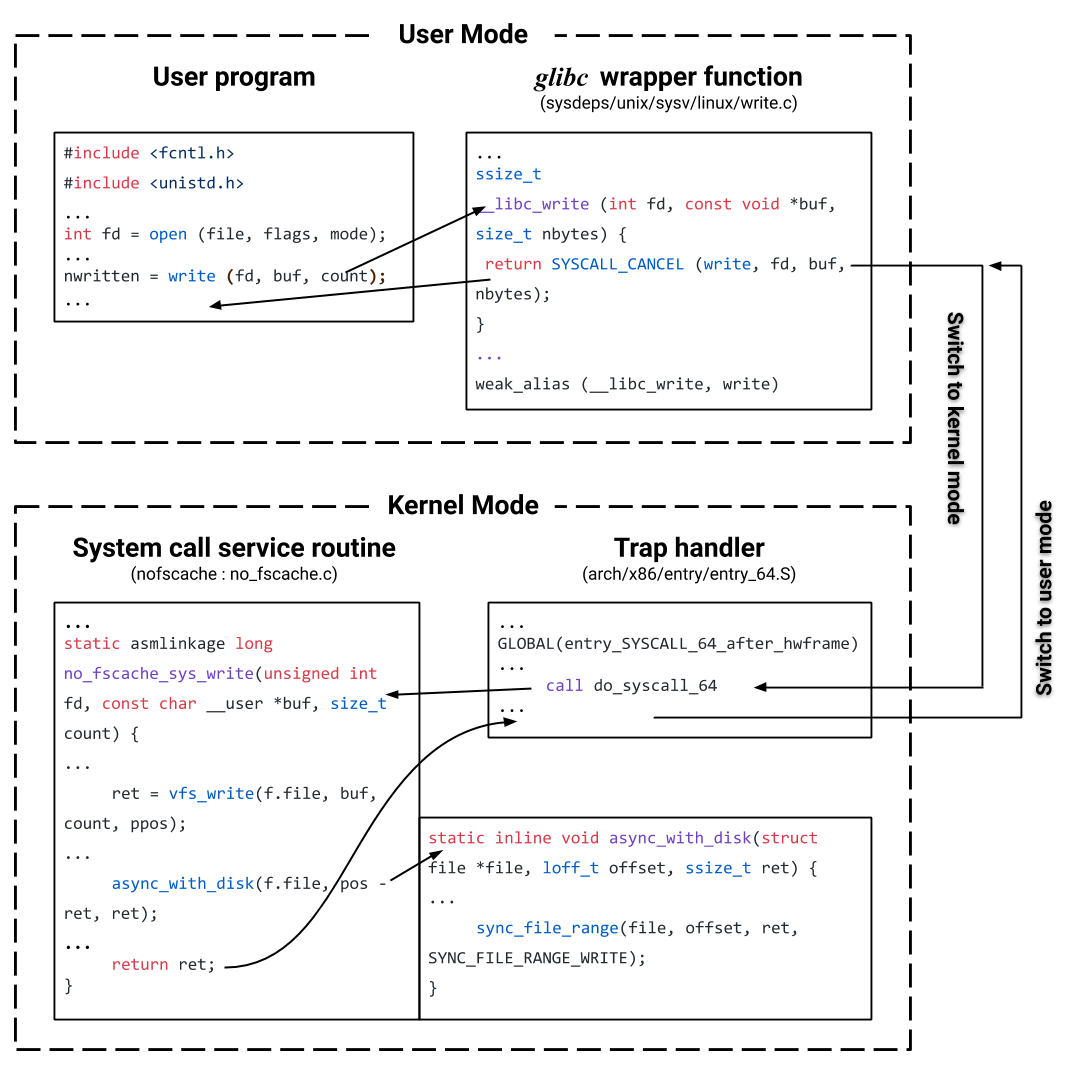
Figure 3: Four Linux I/O Models
4. These I/O models share the same set of system call interfaces: read(2)/write(2), pread(2)/pwrite(2), preadv(2)/pwritev(2), and preadv2(2)/pwritev2(2).
5. POSIX AIO provides asynchronous interfaces, namely aio read(3)/aio write(3), corresponding to read(2)/write(2).
6. Libaio consists of three main system calls: io setup(2), io submit(2), and io getevents(2).
7. Io uring introduces future-rich interfaces to provide functions that existing interfaces were lacking. The main interfaces are io uring setup(2)/io uring enter(2).
The synchronous non-blocking and asynchronous blocking I/O models share the same set of system calls with the synchronous blocking I/O model. They use status flags O_NONBLOCK or O_NDELAY in the call of open(2) to get a file descriptor for the specified file with path name. The use of these status flags causes the read/write system call with the file descriptor no longer blocking on waiting for returns. Instead, each request will return an error code and callers can use this value to check whether the request is satisfied. In practice, a program that interacts with non-blocking file descriptors usually takes one of the following two approaches to get final results. The first one requires the program to busy-wait until the data is available. This can be extremely inefficient because the program wakes up frequently and most of the time consumes CPU cycles unnecessarily. The other approach improves the utilization of system resources by leveraging poll(2) or select(2) to get notifications when the data is ready, which is why this usage is preferred by most programs. Although these two flags introduce non-blocking I/O for read and write operations, as of today they have no effect for regular files and block devices [11]. Block device activities still block and work in the same way as the synchronous blocking I/O model does. Therefore, our cache elimination method is implicitly applicable to these two I/O models.
Over the years, the feature of asynchronous I/O (AIO) has been implemented in many ways to cover demands from various applications. POSIX AIO is the most stable approach integrated in glibc [12] running in the user-space. Relying on the portability of glibc, this AIO model works on all kernel filesystems with buffer I/O. Internally, POSIX AIO is implemented with a pool of threads that issue I/O requests concurrently. This concurrency gives user applications an illusion that I/O requests are asynchronous, but each thread within glibc actually uses synchronous system calls and follows the synchronous blocking I/O model. Since our implementation to eliminate the page caching effects works in the kernel space, it is seamlessly applicable to the POSIX AIO model. Libaio is another Linux native AIO interface. Applications that want to use this interface typically need to use the libaio library in addition to the glibc. This library is notorious for its incompatibility with buffer I/O in many scenarios, and is known to be relegated to a niche corner that can only reliably work with direct I/O [13, 14, 15, 16]. Given the limitation of this interface, it is safe to say that libaio is not suitable for buffer I/O. Because direct I/O does not generate page cache, our caching effect elimination method is implicitly applicable to this I/O model as well.
Io_uring is the latest AIO model supported by Linux kernel since version 5.1 [17]. Io_uring not only supports direct I/O, but also supports buffer I/O. The introduction of this I/O interface is thought to be promising since applications doing I/O with this new interface can have better performance along with better scalability. Our caching effect elimination method does not work with this I/O model because the populated page caches could be used by subsequent requests before the cache elimination logic takes into effect. However, since io_uring was first released in May of this year, it is still under heavy development including work in stability and performance related issues [18, 19]. We think few applications have adopted this new I/O model. Considering the ease of use and feature-rich of this model, we envision it will gradually be accepted by many more applications, and we will eventually apply our cache elimination method to this model.
System Call Redirection
We have discussed how we augment the original I/O system calls by adding additional functionality to the end of these calls to eliminate page caching effects. There is one last problem we have not considered: how to make the Linux kernel to invoke these augmented system call functions instead of the original ones. Considering automating performance evaluation is one of the goals that the MBWU-based evaluation prototype aims for, we do not want to customize the kernel and use it as part of the evaluation process. Therefore, it requires our changes to the system calls can be injected into a vanilla kernel at runtime. Implementing a loadable kernel module to transparently change the I/O behavior on a specified storage device is an ideal solution given the mature mechanism of dynamic module loading and unloading provided by Linux. However, overriding kernel functions with loadable modules is challenging. There are at least three aspects are required to be considered. First, we cannot break the compatibility of the POSIX I/O interfaces. Once a system has loaded our kernel module, applications on this system should be applied transparently with new changes added by the kernel module without modifying the application source code. Second, not only the software compatibility is important, but also changes that override the built-in kernel functions should be consistent with existing system security policies and robust regardless of different computer hardware. For example, remapping system calls in the Linux syscall table to different function handlers is a way to bind system calls to customized functions. However, the syscall table was set to be read-only for security purposes by default in kernel 2.6.16 [22] and, since then, remapping system calls in newer kernels became tricky without breaking the security policy. Though there are methods such as disabling the write-protection of the table by toggling a bit in the register of the host CPU, this change is CPU architecture-dependent, and turning off this bit will also affect the kernel preemption support [20]. Finally, the overhead of redirecting the system calls should be negligible in most situations and ideally equivalent to the overhead of a few lines of assembly code.
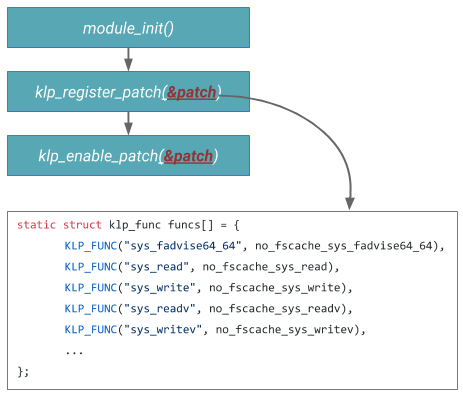
Linux kernel provides a mechanism called “livepatch” to allow function calls to be redirected dynamically with low overhead [21]. It is built with the initial purpose that applying patches to kernel vulnerabilities (e.g., meltdown and spectre) without rebooting the system. This feature offers an entire framework to create kernel modules to modified loaded kernel functions. We developed our caching effect elimination module based on this framework. Figure 4 shows the execution of POSIX read() after sys_read() is patched by this using this mechanism.
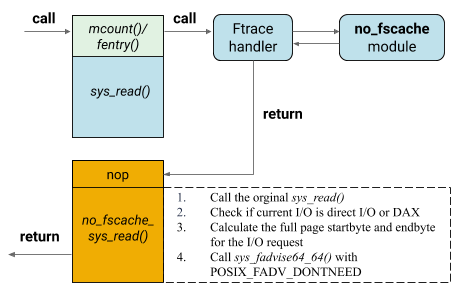
Function mcount() or fentry() is generated by GCC’s profiling mechanism [23]. It is prepended to all non-inlined kernel functions during the kernel compile time. Old version of GCC generates mcount() and new version of GCC generates fentry(). These entry-point functions are used as trampolines for hooked functions if they exist, but are replaced with assembly instruction NOPs as part of the system boot process to reduce the function-call overhead. There are different ways to restore these entry-point functions after the system booted. A kernel livepatch module can register a kernel function to be overwritten, this function will have a restored entry-point function once the module is loaded. Take the example shown in the figure when the system call sys_read() is triggered by a POSIX read(2) from user-space; function mcount() will be called at the first place before the parameters of sys_read() or the stack of it is in any way modified. The call then redirects the execution to a customized ftrace handler from the livepatch framework to decide which function should be called in the next step. Since our module, called no_fscache, has registered to replace the function sys_read() with function no_fscache_sys_read() defined in the module during the module initialization process (Figure 5), the handler will put the instruction pointer to this new function. Once the new function is executed, the kernel continues the system call routine by leaving from this function instead of the original sys_read().
Evaluation
We used the flexible I/O tester, namely “fio”, to compare the performance when our no_fscache kernel module is loaded, with the performance when we limit the memory for page cache. To limit the memory, we used interfaces in the memory controller from the control group (“cgruop”). Cgroup is a powerful Linux kernel feature [9]. It works by assigning a process to a cgroup, which has memory restriction policy defined. The memory controller accounts the process’s memory usage including anonymous pages and cache pages managed by the virtual memory subsystem.
Noted that we used cgroup only for performance verification instead of using this strategy as a general solution to control page caching effects for applications. It is because in the verification we know what application and what workload to run, and we can limit the memory of corresponding processes based on the observations from multiple runs. While in the general performance evaluation, we do not know what application will be tested and how much memory the application will use. There is no single memory throttle that fits for every application without limiting the memory requirement of the application. In our verification with fio, we manually set the available memory for the test process to the normal memory usage of the process.
Experiment Results
The testbed is a bare-metal server from CloudLab Utah [24]. The machine type is m510, which has 16 vCPUs @ 2.00GHz, 64GiB DDR4 memory, a Toshiba NVMe drive, and it runs with kernel 4.15.0. All the tests are done on an ext4 filesystem that is mounted on the NVMe drive. The tests include sequential read and write, random read and write, and a combination of read and write workload. We summarized the results in Figure 6.
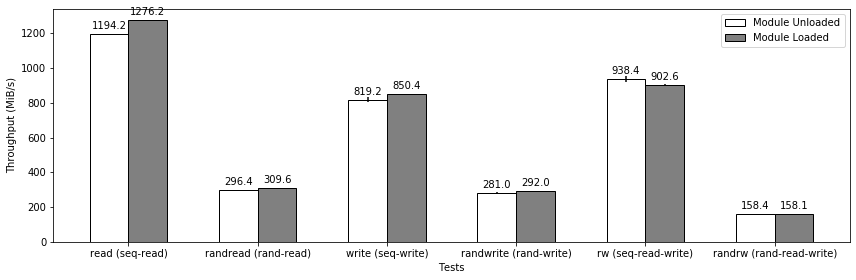
Results from module unloaded were tested under memory restriction using cgroup. Results from module loaded were tested with normal system configuration except that our no_fscache module was loaded beforehand. For the sequential tests, we used a block size of 256 KiB. For the random tests, including the tests of random read and random write, and the test with mix operations, we used a block size of 4 KiB. The “iodepth” in the fio job file was 16 as this is more of a practical configuration in real-world applications. We used the “sync” ioengine for all the tests because it employs interfaces from the synchronous blocking I/O model. Each throughput number in the figure is the average result of 5 runs in steady-state, with each run of one-minute duration. Before starting a test, we first discarded all blocks on the drive and then zero-filled the entire user capacity of the drive. This step ensured that all the measurements start in the same state of the drive. The memory limit on the process of fio was 48 MiB for read tests and 96 MiB for write tests. Write tests required more memory because fio maintained the buffer of pre-initialized file contents used by write requests.
Comparing the results from testing when the module is unloaded, with results from testing when the module is loaded, the differences between them are within 10% for all 6 tests shown in the figure. These results demonstrated our approach can precisely emulate the I/O performance of these test workloads under insufficient memory for the page cache, which means that it can achieve our initial goal as to eliminate the page caching effects.
Though we have not yet tested any real-world applications with this kernel module, which will be included as future work, we believe the results will be similar given the positive results we currently have. We are also going to work on making this module to be compatible with the latest AIO model using the io_uring interfaces.
Conclusion
We developed a Linux loadable kernel module to effectively eliminate external caching effects to assist the MBWU construction for real-world workloads. It works by emulating the I/O behavior of a given test workload running under insufficient memory for the page cache. It only affects buffer I/O and has zero impact on any direct I/O because direct I/O does not generate page cache. This module is built by leveraging the kennel livepatch framework with which system call behavior can be changed transparently to any user applications. The use of this kernel module is part of the MBWU-based evaluation prototype, which automates the performance comparison between different platforms that run a given workload on the same storage media.
References
[1] Samsung Electronics Co., Ltd. Samsung PM863a/SM863a SSD for data centers, November 2016.
[2] top(1): tasks - Linux man page. https://linux.die.net/man/1/top.
[3] iostat(1) - Linux man page. https://linux.die.net/man/1/iostat.
[4] sar(1) - Linux man page. https://linux.die.net/man/1/sar.
[5] Wikipedia contributors. Page cache — Wikipedia, the free encyclopedia. https://en.wikipedia.org/w/index.php?title=Page_cache&oldid=919726591, 2019. [Online; accessed 4-November-2019].
[6] Mike Snitzer. I/o limits: block sizes, alignment and i/o hints. https://people.redhat.com/msni tzer/docs/io-limits.txt.
[7] Considerations for the use of direct I/O (O DIRECT). https://www.ibm.com/support/knowledgecenter/en/STXKQY_4.2.0/com.ibm.spectrum.scale.v4r2.adm.doc/bl1adm_considerations_direct_io.htm.
[8] Documentation for /proc/sys/vm - the linux kernel archives. https://www.kernel.org/doc/Docum entation/sysctl/vm.txt.
[9] Cgroups - the linux kernel archives. https://www.kernel.org/doc/Documentation/cgroup-v1/memory.txt.
[10] sync(8) - Linux man page. https://linux.die.net/man/8/sync.
[11] open(2): open/possibly create file/device - Linux man page. https://linux.die.net/man/2/open.
[12] aio(7): POSIX asynchronous I/O overview - Linux man page. https://linux.die.net/man/7/aio.
[13] Jens Axboe. Efficient io with io uring. https://kernel.dk/io uring.pdf.
[14] Jonathan Corbet. Toward non-blocking asynchronous I/O [LWN.net]. https://lwn.net/Articles/724198/.
[15] Jonathan Corbet. Fixing asynchronous I/O, again [LWN.net]. https://lwn.net/Articles/671649/.
[16] Jonathan Corbet. A retry-based AIO infrastructure [LWN.net]. https://lwn.net/Articles/73847/.
[17] Linux 5.1 - Linux Kernel Newbies. https://kernelnewbies.org/Linux 5.1.
[18] Jens Axboe. [PATCH] io uring: don’t use iov iter advance() for fixed buffers - Jens Axboe. https://lore.kernel.org/linux-block/d13f2023-4385-cb30-46d4-a2221d5b6267@kernel.dk/.
[19] Philip Kufeldt, Carlos Maltzahn, Tim Feldman, Christine Green, Grant Mackey, and Shingo Tanaka. Eusocial storage devices: Offloading data management to storage devices that can act collectively. ; login:, 43(2), 2018.
[20] Nur Hussein. The “rare write” mechanism [LWN.net]. https://lwn.net/Articles/724319/.
[21] Livepatch - the linux kernel archives. https://www.kernel.org/doc/Documentation/livepatch/livepatch.txt.
[22] kernel/git/history/history.git - Linux kernel historic tree. https://git.kernel.org/pub/scm/linux/kernel/git/history/history.git/commit/?id=bb152f53120d66c98c1f16518407df6a84f23714.
[23] Richard M Stallman et al. Using the gnu compiler collection. Free Software Foundation, 4(02), 2003.
[24] Robert Ricci, Eric Eide, and CloudLab Team. Introducing cloudlab: Scientific infrastructure for advancing cloud architectures and applications. ; login:: the magazine of USENIX & SAGE, 39(6):36– 38, 2014.
